To holistically assess Large Vision-Language Models (LVLMs) fine-grained visual understanding capabilities, we propose using document images
with multi-granularity and multi-modal information to supplement natural images.
In this light, we construct MMDocBench, a benchmark with various OCR-free document understanding tasks for the evaluation of fine-grained visual perception and reasoning abilities.
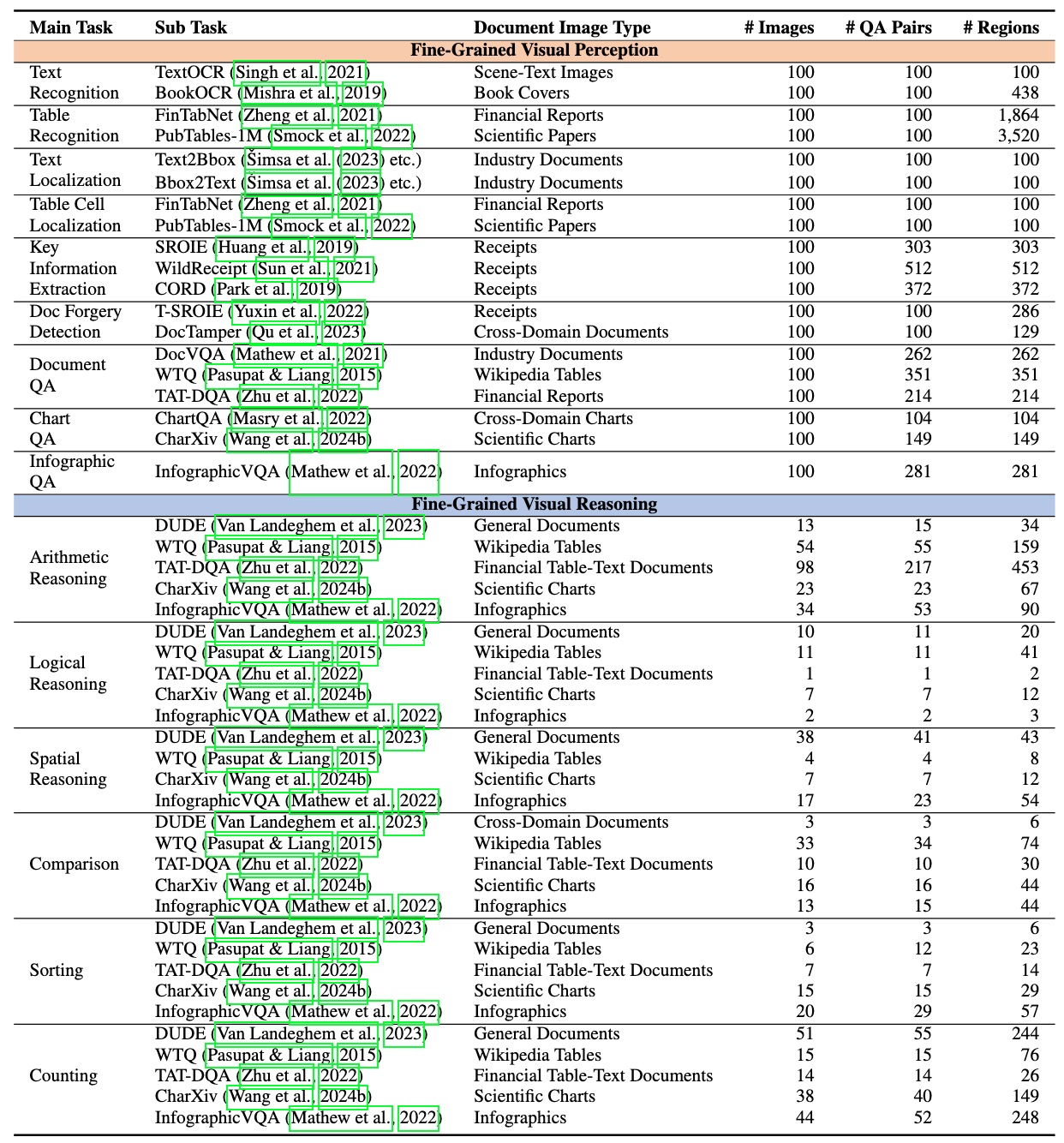
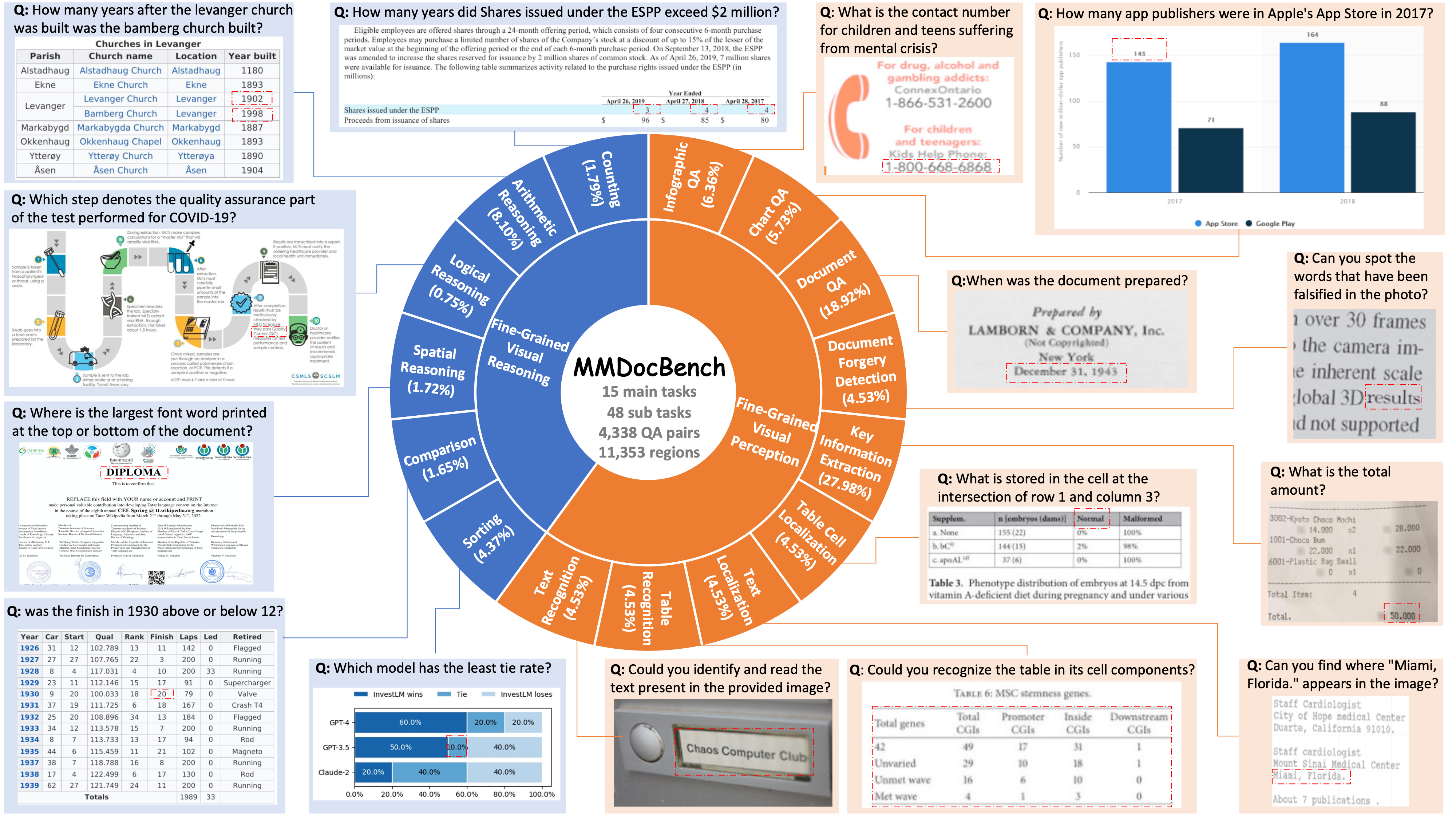
MMDocBench defines 15 main tasks and 48 sub tasks, covering various document images such as research papers, receipts, financial reports, Wikipedia tables, charts, and infographics.
Additionally, in MMDocBench, we also provide annotations of supporting regions (i.e., bounding boxes) within the image for each QA pair. The supporting regions enable the evaluation of whether LVLMs have correctly grounded their predictions on the associated regions in the image, leading to a more comprehensive evaluation.
The output of supporting regions can offer significant practical value, making the LVLMs' responses more informative and interpretable while allowing for rapid cross-checking between the answer and the image.
Finally, MMDocBench contains 2,400 document images, involving 4,338 QA pairs with 11,353 supporting regions.
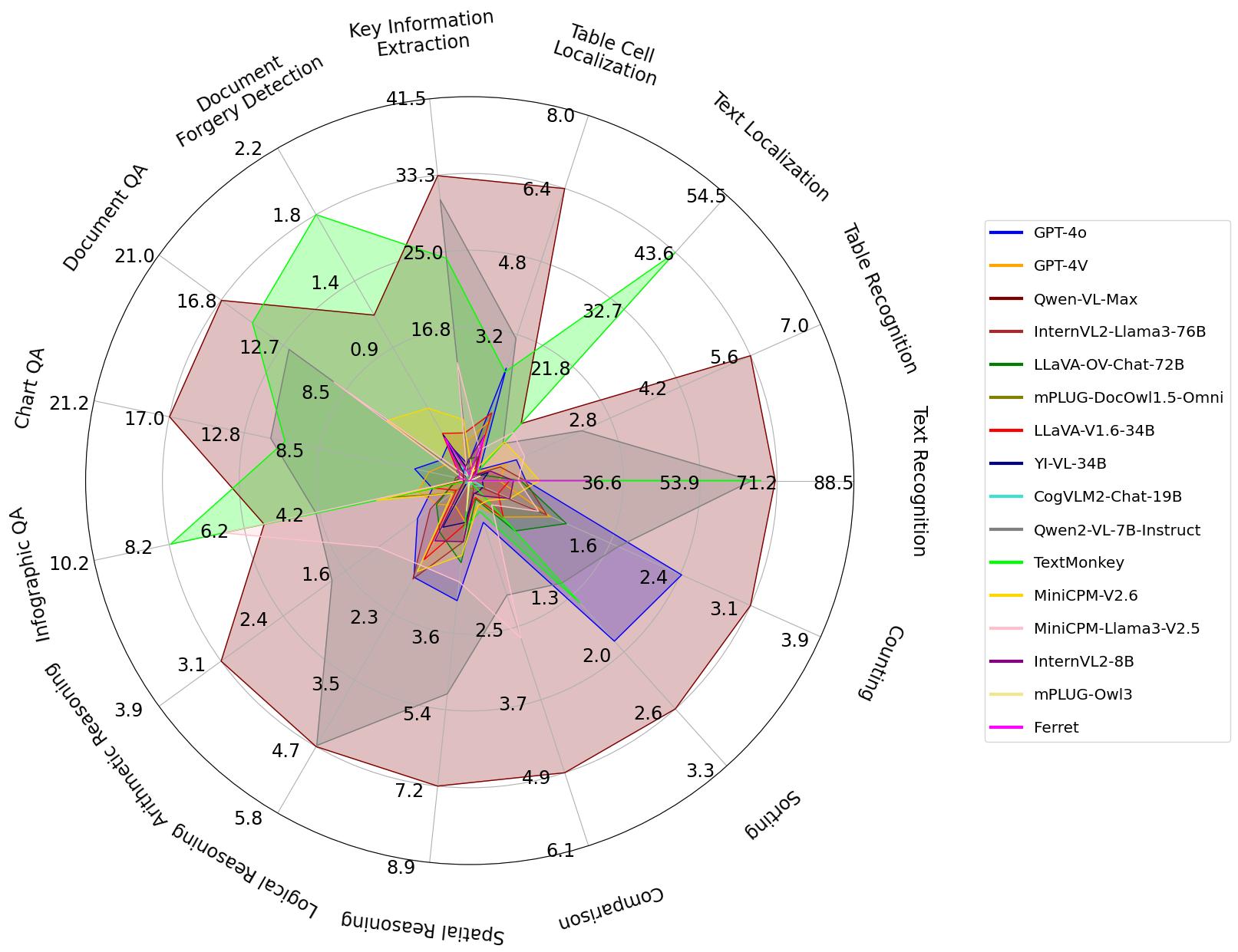
Based on MMDocBench, we conduct extensive experiments using 13 open-source and 3 proprietary advanced LVLMs, assessing their strengths and weaknesses across different tasks and document image types.
We believe MMDocBench can enable a thorough and multi-faceted evaluation of fine-grained visual document understanding of LVLMs, thereby facilitating LVLMs' future advancement.